Visualizing my Wikipedia Browsing History
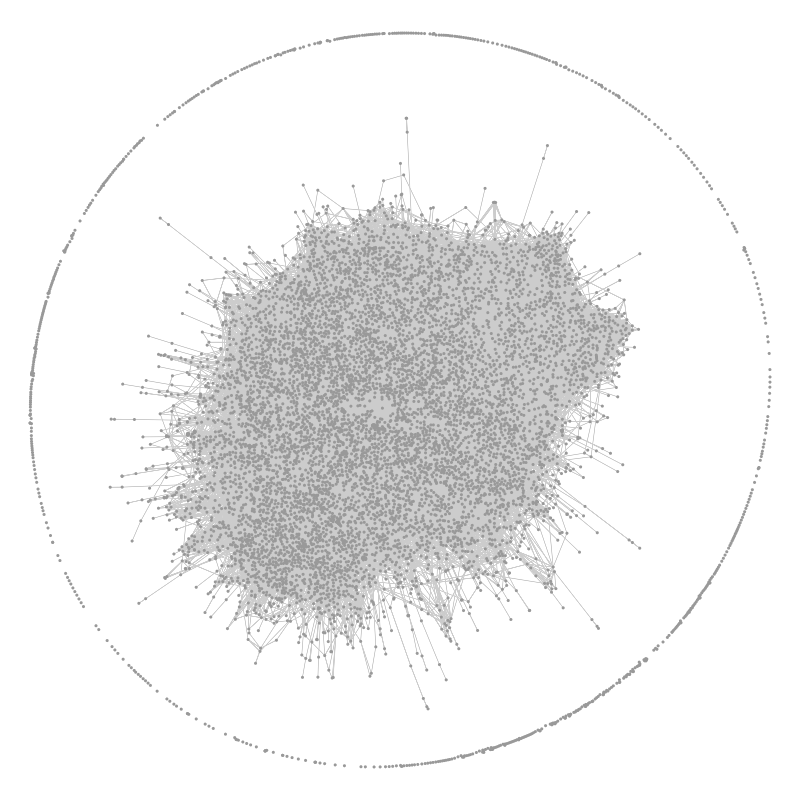
Full network graph. Ring is pages not connected. The dense inner web demonstrates how highly connected wikipedia pages are
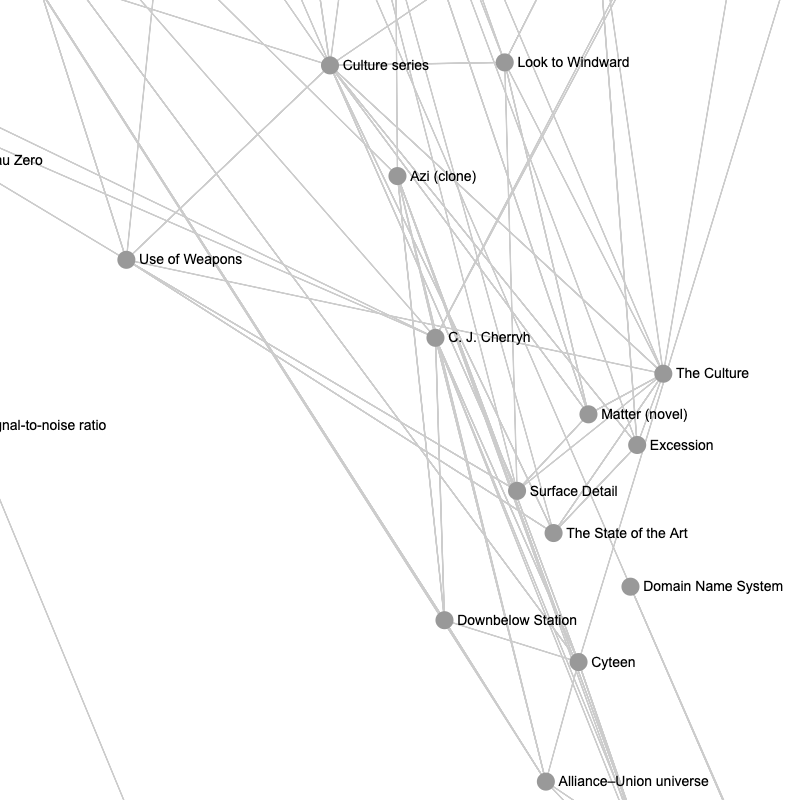
Zoom in on my favorite author: Iain Banks and the Culture series
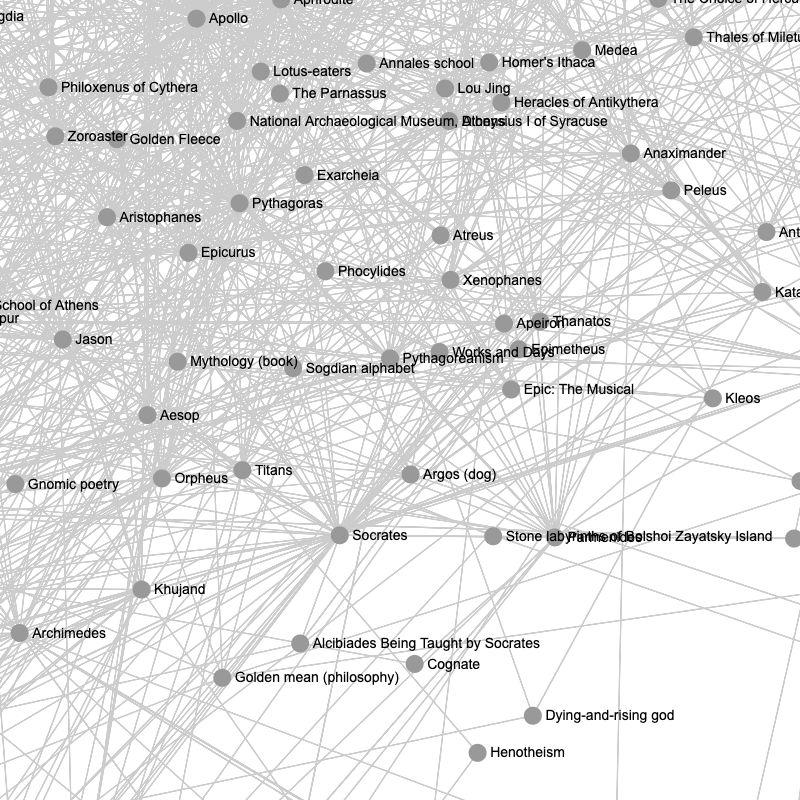
Cluster of ancient Greek philosophy and history
Backstory
I have been intentionally changing my internet browsing history the past few years, aiming to reduce endless scrolling on "junk food" sites. This year in particular, I quit reddit and twitter, and have instead been reading just the news and wikipedia. This has worked as a gradual reduction in satisfaction: the news, while interesting, lacks the same level of excitement as a silly debate on reddit or "hot take" from a personality on twitter. I regularly browse the Wikipedia "Did you know..." and "This day in history," finding it scratches the itch of new content, while again lacking the compulsive pull that lost me countless hours previously.
As a result, I have visited about 10,000 wikipedia articles. As a creative programmer, I was inspired to dive into this data set - could I visualize the connections between pages, for example?
Approach
Two books played a large role in this project coming to fruition. Nexus by Mark Buchanan explores network theory, explaining various network topologies and applications to the real world - hence my interest in modeling my browsing history as a network. On the creative side, I recently started The Artist's Way by Julia Cameron, with the intention of recovering the artist within me. One key challenge for me is perfectionism: I bring my professional background, but more than that, I bring high standards to what are casual and fun projects.
I think that llms can be a boon for creative blocks and perfectionism. I started a chat with a prompt that explained my default tendencies, such as over-engineering, getting lost in details, and struggling to finish and publish. I then worked with intention, describing my actions step by step, and getting helpful feedback and perspective - the llm caught a few moments where I almost went down a rabbit hole. Most notably, the llm suggested I call the project done and write this article. I believe that llms can be utilized to great benefit for people skilled at introspection: knowing my blindspots and tendencies, and communicating with honesty and accepting the feedback, I'm able to break unskillful patterns of behavior.
Technical details
The high level technical approach was as follows:
- Get my wikipedia browsing history
- Build a network data structure where articles are nodes and links between articles are edges
- Visualize the network
Browsing history
I don't have an account on wikipedia, but I don't believe that browsing history is tracked with an account anyway. I do use firefox with sync across desktop and mobile, which conveniently syncs browsing history - important because I visit wikipedia on multiple devices. I therefore built a browser extension, which enabled retrieving history, and a convenient interface for visualizing in the browser via extension pages.
The extension uses a browser action to open an extension page - i.e. the toolbar extension button opens a new tab with content from the extension. The technical details for this approach are scattered across the mdn docs and examples, here's the basics.
Here's my manifest.json:
{
"manifest_version": 2,
"name": "Wikitrack",
"version": "0.1",
"description": "Visualize wikipedia browsing history.",
"browser_action": {
},
"background": {
"scripts": ["background-script.js"]
},
"permissions": [
"history"
]
}
The relevant bits are defining the browser_action entry (it can be empty for a simple extension) and the background scripts. Here's background-script.js:
function listener () {
browser.tabs.create({
url: "page.html",
});
}
browser.browserAction.onClicked.addListener(listener)
This defines a listener on the browser action, opening my page.html when the toolbar button is clicked. Great. The html is basic and references a javascript file that grabs the history (because extension pages have access to the same permissions as the extension):
function onGot(historyItems) {
console.log("Found " + historyItems.length + " wikipedia pages visited");
}
browser.history
.search({
text: "wikipedia.org",
startTime: 0,
maxResults: 1000000,
})
.then(onGot);
Awesome! I am able to get a list of all wikipedia pages that I've visited.
Network
With the browsing history, the next step was to build a network data structure that included links between pages as edges. To get the links, I needed to get each article's content. There were a few approaches that I could've taken, the simplest most likely scraping the live wikipedia site to retrieve each article's content. At the scale of 10k articles, mindful of rate limits, and maybe a little overengineering, I decided to take the approach of parsing the full english wikipedia data dump instead.
This came with some challenges: as the data dump is 100gb decompressed, the suggested method is to use an index into the compressed file, and decompress only what's necessary. This seemed technically challenging and therefore a potential rabbit hole, so I chose to decompress the file and stream parse the xml. I tried various tools, including xmlstarlet, xmllint, and python's builtin xml parser, before settling on lxml: with stream parsing, lxml processed up to 50k articles per second. At roughly 25 million articles total, processing the entire 100gb xml file took about 9 minutes. This was perfectly reasonable for my use case: find articles that I've visited and output the article content.
Here's the script that stream processes the xml, writing a jsonl file with article contents:
import json
from lxml import etree
from tqdm import tqdm
page_estimate_count = 25_040_290
visited_page_titles = set()
pages_found_in_xml = set()
pages_found_in_xml_count = 0
with open("history.cleaned.json", "r") as history_file:
## history.cleaned.json is a json list of article titles, cleaned and filtered (e.g. special pages removed)
history_content = json.load(history_file)
visited_page_titles = set(history_content)
print(f"Looking for {len(visited_page_titles)} pages")
with open(
"wikidata/enwiki-20251001-pages-articles-multistream.xml", "rb"
) as xml_file, open("history.pagecontent.jsonl", "w") as pagecontent_file, tqdm(
total=page_estimate_count, desc="Processing pages", unit="pages"
) as pbar:
for event, elem in etree.iterparse(xml_file, events=("end",)):
if elem.tag.endswith("page"):
# get title + text
title_el = elem.find(".//{http://www.mediawiki.org/xml/export-0.11/}title")
text_el = elem.find(".//{http://www.mediawiki.org/xml/export-0.11/}text")
if title_el is not None and text_el is not None:
page_title = title_el.text
page_content = text_el.text
if page_title in visited_page_titles:
pages_found_in_xml.add(page_title)
pages_found_in_xml_count += 1
pbar.set_postfix(found=pages_found_in_xml_count)
pagecontent_file.write(
json.dumps(
{
"title": page_title,
"content": page_content,
}
)
+ "\n"
)
pbar.update(1)
# Free memory as you go
title_el = text_el = None
elem.clear()
# Remove references from parent to enable garbage collection
while elem.getprevious() is not None:
del elem.getparent()[0]
print(f"Found {len(pages_found_in_xml)} pages from history in the xml")
print()
Of note, stream processing via .iterparse() does not free memory automatically. Instead, memory for each element has to be explicitly freed via elem.clear() - however this only frees its children, not itself, so the references to the element from the parent also have to be explicitly removed. All together, this script uses 40-80mb of memory, quite impressive for processing a 100gb file!
tqdm, with the ability to specify a total and custom postfix content, provided an excellent interface:
% python graph.py
Looking for 9051 pages
Processing pages: 3%|██▋ | 689010/25040290 [00:26<11:13, 36150.31pages/s, found=3553]
The next script parsed each article's content using mwparserfromhell, extracting links, and built a simple network data structure, mapping each article to its linked articles (limited to articles I've visited, i.e. no new nodes are introduced):
import json
from collections import defaultdict
import mwparserfromhell
def is_valid_link(link):
# Filter out images, categories, and non-internal links
return not str(link.title).startswith(
(
"File:",
"Category:",
"Talk:",
"User:",
"Template:",
"Help:",
"Portal:",
"Draft:",
"TimedText:",
"MediaWiki:",
"Module:",
"Special:",
)
)
pagecontent = []
with open("history.pagecontent.jsonl") as pagecontent_file:
for line in pagecontent_file:
pagecontent.append(json.loads(line.strip()))
full_graph = defaultdict(set)
for page in pagecontent:
wikicode = mwparserfromhell.parse(page["content"])
links = []
for node in wikicode.filter_wikilinks():
if is_valid_link(node):
links.append(node)
full_graph[page["title"]].update(str(link.title) for link in links)
interested_pages = set(full_graph.keys())
interested_graph = defaultdict(list)
for interested_page in interested_pages:
edges = full_graph[interested_page]
interested_edges = edges.intersection(interested_pages)
interested_graph[interested_page] = list(interested_edges)
with open("history.graph.json", "w") as graph_file:
json.dump(interested_graph, graph_file)
After about a minute, I have my graph data structure, ready to visualize!
Visualization
For visualization of a network in the browser, I first tried vis.js, but it choked under the load of 10k nodes and 20k edges, so I went with Sigma.js, which is better suited for this network size. Keeping it simple - no webpack or bundling - I downloaded the graphology and sigma js and loaded them directly into the html. It's amazing how fast development can be without all the cruft of modern tooling!
For loading the data, again I took a simple approach and manually edited history.graph.json to a javascript file that exports the json, and loaded the javascript file into the html. The code to render the graph is thus:
$(document).ready(function () {
const container = document.getElementById('network');
// graphData is exported implicitly via js file
// sigma.js
const graph = new graphology.Graph();
// Add nodes
Object.keys(graphData).forEach(node => {
graph.addNode(node, { label: node });
});
// Add edges
Object.keys(graphData).forEach(source => {
graphData[source].forEach(target => {
graph.addEdge(source, target);
});
});
// Position nodes on a circle, then run Force Atlas 2 for a while to get proper graph layout:
graphologyLibrary.layout.circular.assign(graph);
const settings = graphologyLibrary.layoutForceAtlas2.inferSettings(graph);
graphologyLibrary.layoutForceAtlas2.assign(graph, { settings, iterations: 600 });
const renderer = new Sigma(graph, container);
});
Voila! From 0 to a visualization in a weekend.
Closing thoughts
I actually did rediscover some of the joy that I used to have with programming, way back in college when I "didn't know better": poorly written scripts that glue together through tedious manual processes, pulling in dependencies in the simplest way possible (pip install and downloading the js), settling for "good enough" hacks that get the job done. "Done is better than perfect" comes to mind, as I can publish this article today instead of never.
Some follow-up projects that come to mind:
- Improved visualization and exploration of visualization techniques
- Professionalize the project, bundle and ship it for others as an extension and web api
- Building an interactive network UI, with filtering and timeline support
- Clustering and labeling
- "Missed connections": suggest articles that are related to articles I've visited
- Sessions: visualize individual browsing sessions
More to come?
Data sources
This project uses data from Wikipedia, available under the Creative Commons Attribution-ShareAlike License. The English Wikipedia database dump was obtained from Wikimedia Downloads.